
90%的客户都是回头客。
Instacart是如何做到的?它如何利用数据科学获得利益最大化?(案例资料图片等取自Instacart数据科学副总裁)。
在开始探寻这些问题之前,先来看下它的商业模式,正是因为这种独特的模式,才让它成为值得研究的经典案例。
Instacart的商业模式
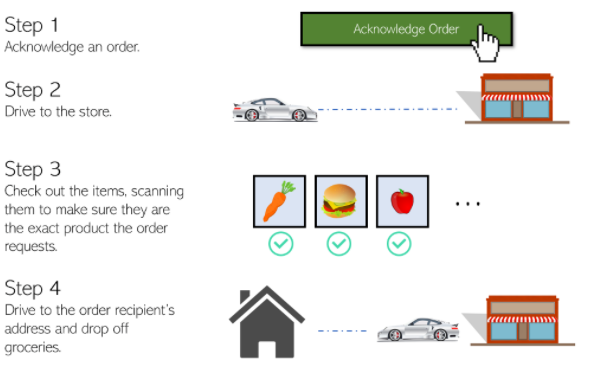
Instacart的价值主张很简单,就是-1个小时内将商品送到您家门口。如果你是初次使用Instacart的客户,下面就是你需要经历的流程:
1、下载Instacart应用程序。
2、选择一家商店。比如Whole Foods,Costco,Petco,Wegman’s等。
3、从商店的库存中,选择要添加到购物车中的商品。
4、选择一个你希望货物送达的时间范围。(范围一般是1小时的区间内,每个时间段间隔1小时)

提交订单后,1小时送达!整个流程从UI上看是不是很顺畅又方便?
但代购员的体验就相对要复杂点。
1、在Instacart应用程序中,对代购员实行轮班制,根据系统分配的不同订单进行工作。
2、根据订单制定的商店以及商品清单进行购买。
3、按照清单挑选后,进行扫码以确保商品没有挑选错误。
4、最后,代购者进行结账并将商品送往指定地址。
从上述可以看到有两个明显的市场主体——代购者和客户,但Instacart实际上具有4个市场主体,你能想到另外两个吗?

产品广告商和商店。
其中的每一方都能以某些方式与其他三个主体进行交互。下图的每一个箭头都是提升业务的机会。


(图源:Jeremy Stanley)
Instacart的收入形式主要有:
·配送费。比如可能需要花费5美元,如果想免配送费,可一年$150购买会员;
·用户支付的服务费、小费,这些用于支付代购者的人工费。但实际上并不够。
·与宝洁以及类似的品牌广告公司合作。商品销售额中大约30%是分给广告主的。
·从零售合作伙伴中获得部分利润。比如像Whole Foods,Instacart为他们带来流量,他们也会为此进行投资。
但是Instacart也有一定的支出成本,例如交易,信用卡处理和保险。不过,最大的成本就是代购员的购买以及配送的时间。
如果想获取更多利润,Instacart就需要让系统运行更高效,更快。因此,这是主要目标。
据Instacart数据科学副总裁介绍,优化后台后的效率提升了40%,所带来的效果比较可观:
·客户平均每月花费约500美元,Instacart使用频率提升。
·90%的客户是回头客。
了解了它的商业模式之后,接着来谈谈它如何利用数据科学解决业务上所面临的挑战。
影响预测出现差异的不可控因素很多
比如在送货的路上遇到了堵车或者路障,代购者就会送货延迟,相应的,客户的满意度就会下降。

在诸多因素里面,天气是一个很大的不可控因素,比如天气很冷的时候,客户不想出门购买商品,使用Instacart的需求也会随之变高。但是,代购员也可能因为天气原因,选择休息,他们的需求就会降低。而天气很好的时候则反之。
不仅是Instacart,全美50%的杂货店都会因为天气而困扰。
此外还有两个变量也会造成影响,结帐时的排队长度以及配送地点可使用的停车位。
这些因素会造成数据中产生巨大的差异,想进行预测就很困难。
由上述来看,Instacart主要面临着两个挑战。
首先是如何平衡供需关系?
就像上述受天气影响所造成的问题一样,供需两方经常相互冲突而不是处于平衡状态。需求太多而供应不足,会降低客户的满意度和忠诚度,供应过多但需求不足,会导致公司生产力以及效率下降,从而影响到利润获取。
第二个则是供求关系已经达到平衡,代购员如何选择尽可能高效的送货路线?如何根据位置去进行不同的订单分配,让代购员的效率达到最大化,还能够确保商品准时送达?
需求难以衡量
对于任何一个企业而言,衡量需求至关重要,它影响到后续运营工作的评估以及优化。但对Instacart而言,完全做到这样比较困难。
当客户使用Instacart时,他们会希望在某个时段收到自己购买的商品,但这可能就会造成某个时段会累积很多的订单(高峰时间),而代购员没办法处理这些订单。
为了解决这个问题,Instacart实行了高峰时间段的定价”,如果用户希望在某个高峰时段收到商品,就需要支付比其他时段更高的费用。
因此,Instacart使用机器学习模型来预测什么时间是订单高峰,什么时间是订单偏少的时间段,当高峰时间段订单满了之后,Instacart将取消配送;相对应的,在订单量比较少的时候,会提供折扣优惠。

每个Instacart访客基本上可以分为以下三种情况:
- 继续进行结帐。
- 想结帐,但想要的送货时间段不可选。
- 当前没有购买意向,只想浏览App,可能会在之后进行购买。
在上述的情况下,所有人都浏览界面,那么如何区分具有真实购买需求和没有购买意向,只是看看的用户?

注意:“需求计数”是指已计算或已知的需求量。在Instacart上购买商品的客户会有购买记录。但是,那些想要购买食品(存在需求)但没有购买任何东西(没有留下任何购买记录)的客户被视为“无法计算的需求”。
由此,Instacart建立一个概率模型来预测访客在一定情况下进行购买的机会。它考虑了市场和用户个体的特征,以及可能遇到的购买场景,比如哪些时间段允许配送?打开了哪些窗口?等等。
如果把每个用户都考虑在内,该模型可以估算出需求:每个用户100%会进行购买,将进行多少次交付?
模型会同时考虑计数的需求和未计数的需求,但是假需求不会包括在内。

使用这种方法,Instacart能够预测需求,以及估算“丢失的交货”量(需求-成功购买的数量)。可看下图橙色部分所示:

图片:Instacart的Jeremy Stan
预测交货时间
Instacart的宗旨就是1小时送达商品,如果没有达到这个目标,就会影响客户满意度。但从下图可以看到,事实上,早于客户预定时间的话,客户满意度会更高。

所以想要提高客户满意度,就需要Instacart解决预测代购员配送时间,以及最优路线推荐的问题。
但由于Instacart代购员并不是简单的使用地图,其中还会包含停车、往返、选购等时间,所以Instacart需要建立自己的行程时间估算器,Google Map并不是特别适合。

资料来源:Instacart的Jeremy Stan
另一个不适合的原因则是,Instacart必须对他们可能考虑的所有路线组合做出预测,而且这些必须在系统内部优化。

是一个内部组件相互通信,且估算器已调整为Instacart特定数据类型的系统,还是需要速度比较慢,使用外部API的系统?图形由Andre Ye创建。
分位数回归是Instacart进行预测的方法。它确定的是第95分位数是多少?或者第5分位数是多少?Instacart的系统考虑了所有步骤中方差的相关性,以预测未来的方差。
为了解决Instacart数据高方差的需求,Instacart使用梯度增强决策树,其具有过度拟合的趋势性。
现在预测时间的问题解决了,如何制定路线?
推荐配送路线
假设需要匹配300个订单和100个代购员。即使每个人配送3个订单,还是有4.45亿个配送组合。
每一分钟对于Instacart都是宝贵的,所以找到最优的组合最为重要。当然,他不会将上述的组合挨个计算再进行选择。
Instacart是将可配送商品的数量最大化。
在许多主要城市,同一个商店位置可能不太相同,但商品一样的话,代购员可以选择最近的一家店进行购买。

但库存并不总是实时更新过的,Instacart根据订单评估商店地址时,会以用户为主,选择库存最可能是充足的那家店,而这家店距离不一定是最优的。

但假设Costco#1确实有客户想要的产品,而Instacart也会考虑时间因素,选定最近的店铺,最终就可以准时送达,保证客户的满意度。
对于Instacart来说,第二种方式首要考虑的是订单,也就是利益为先。

实际上,Instacart的首要算法很简单。它基于下面的这个问题:
什么样的配送组合最有可能导致延迟送达?
算法会将一个订单分配给代购员,如果接到了第二个订单,系统将其加在第一个订单之后,其配送时间并不会延迟的话,系统就会确定把第二个订单继续分配给代购员,这个过程会不断继续。
通过高效的机器学习算法,Instacart获得了一定的提升——延迟交付减少了20%,并且高峰时间的百分比增加了20%。
希望这个案例带给各位一些启发~
来源: